【解説】Cloud Composer v2とv3の違いとは?
はじめに
こんにちは。Aimyです👧
Cloud Composer は、Google Cloud 上で提供されるマネージドなワークフローオーケストレーションサービスであり、Apache Airflow を基盤としています。バージョン3(以下、v3)の登場により、Composer の構成方式が大きく刷新されました。
本記事では、Cloud Composer v2とv3におけるネットワーク構成の違いに焦点を当て、設計・運用面での影響や、接続方式の変更点について解説します。
Cloud Composer v2のネットワーク構成
Cloud Composer v2では、環境構築にあたりユーザー自身がVPCネットワークを準備・構成する必要がありました。具体的には以下のような構成要素が含まれます:
- GKEクラスタ(Airflowの実行基盤)
- Cloud SQL(メタデータ保存用)
- Cloud Storage(DAGファイル保存用)
- 専用のVPCネットワークとサブネット
- Private IPによる各サービス間の通信
このような構成により、Composer 環境は他の Google Cloud サービスと安全に連携できる反面、VPC、ルーティング、ファイアウォールなどネットワークの設計・管理が求められる点が特徴です。
特に、他サービスと接続する場合、IPアドレス設計や名前解決などの調整が必要となり、初期構築の工数が比較的高い傾向がありました。

出典:
環境のアーキテクチャ | Cloud Composer | Google Cloud
Cloud Composer v3のネットワーク構成
v3では、Google Cloudが提供する GKE Autopilot 上にComposer環境が自動で構築されるようになり、ユーザーがVPCを準備する必要がなくなりました。構成は大きく簡素化され、基本的な接続性は Google 管理下のインフラ内で担保されます。
ただし、Cloud SQL や BigQuery など、VPC 内にあるリソースと接続する必要がある場合には、「ネットワークアタッチメント(Serverless VPC Access)」という仕組みを用いて安全な接続を確保します。
このネットワークアタッチメントは、Cloud Functions や Cloud Run などの他のサーバーレスサービスでも利用されており、Google Cloud における 標準的な接続方法の一つとされています。
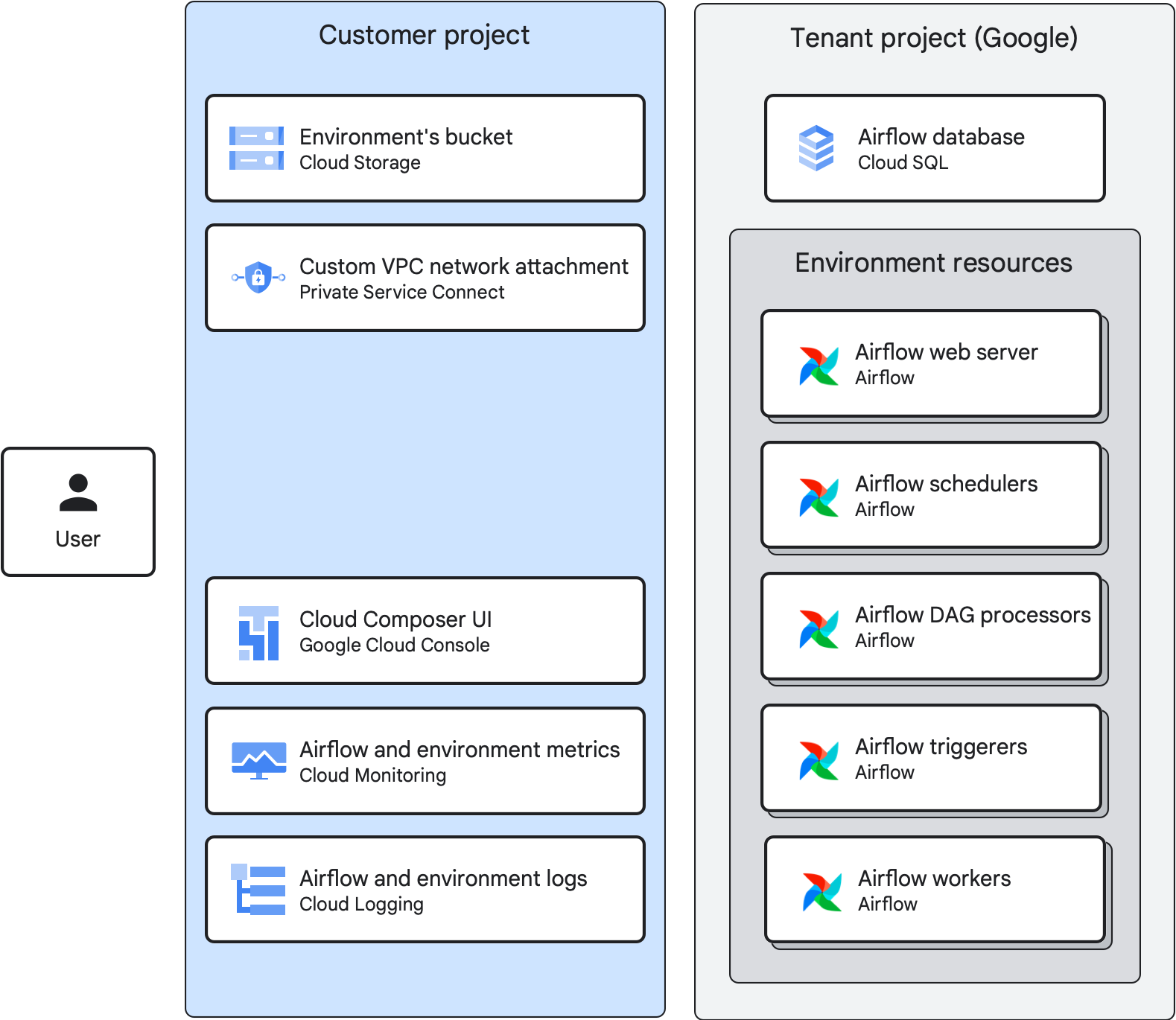
出典:
環境のアーキテクチャ | Cloud Composer | Google Cloud
比較まとめ:v2とv3のネットワーク構成の違い
おわりに
Cloud Composer v3 の登場により、従来必要とされていたVPC構築やクラスタ管理の負担が大幅に軽減されました。ネットワーク構成がシンプルになったことで、Composer環境の導入ハードルも下がり、より多くのプロジェクトでの活用が期待されます。
ネットワーク設計に関する柔軟性が必要な場合はv2、迅速かつ標準的な構成で始めたい場合はv3、といった観点で選択を検討するとよいでしょう。
CloudComposerとはどんなものなのか。について記載した過去の記事も併せてご覧ください。
メディア生成ツール Veo3、Image4、Flow
こんにちは、Takaです。
今日は、メディア生成ツールについて投稿します。
先日、Googleが提供している動画生成ツール Veo3、画像生成ツール Imagen4 が発表されました。さらには、Veo、Imagen、Geminiを統合したAI映像作成ツール Flowも発表されました。
Veo3は、Veo2の品質を向上しただけでなく、なんと動画に音声をつけることを実現しています。日本でも一般公開されているので、是非使ってみてください。
これ生成した動画なのですか?実録ではなくて?恐ろしい世の中です・・・・。
Image4は、最大 2K 解像度の画像を生成できるらしいですよ。解像度がここまであがれば、ポスターとかも作れちゃいます。これ、本当に作った画像なのですか?えぐくないですか?まじでやばいです。。。

Flowは、クリエイターのために開発され、Veo、Imagen、Gemini を統合した AI 映像制作ツールとのことです。はい、もうこれ完全に映画です。。。
先日、ミッションインポッシブルの最新作を映画館で見てきました。トム・クルーズさん62歳なのに、こんなに動けるのすごいと感動しました。でも、もう本当に近い未来に実録無しでも、臨場感ある映画が作れるようになるのでしょうね。
何が現実で、何がフェイクなのかわからなくて怖くなってきました。技術の進歩早すぎます。Soraが東京の街並みを解像度高く描いたのって、まだ1年も前じゃないですよね。
本当に怖い。
参考にしたりんくはこちらです。
じゃ、また!
Taka
AIがAIを更に進化させる
こんにちは、たかです。
やはり、そうなりますよね。という話です。
Google DeepMindが、AIが自らアルゴリズムを発見・進化させる「AlphaEvolve」を発表しました。
この記事によると、Gemini Flash でアイデア候補を作成し、Gemini Proで深く洞察し、AlphaEvoleで検証することで、アイデアを進化させていくとのことです。
300年以上の歴史をもつ行列計算アルゴリズムよりも高速な計算方法を見つけ、50以上の未解決問題を解かせたら、20%で最高解を出したとのことです。
AIが進化させたAIが、更にAIを進化させ、そして更にAIが進化する。
もう指数関数的に成長していくのでしょう。前回のブログで、人間を超えたかもしれないと書きましたが、既に人間が届かない次元にいるのかもしれません。
AIなら戦争も止めてくれるし、飢餓問題も解決してくれるかもしれません。
一般の人が宇宙に出ていく方法だって簡単に確立されてしまいそうな勢い。
ちょっと最近怖くて寝れなくなってきました。
じゃ、また。
Taka
クラウドインフラとハルシネーションの話
こんにちは。たかです。
今日は、クラウドインフラのシェアのお話と、ハルシネーションのお話です。
クラウドインフラのシェア
クラウドインフラ市場全体としては、前年同期比で23%成長、グローバルで940億ドルとのことで、相変わらず高い成長率です。
日本は実績重視でAWSがまだまだ強い状況で、この状況はもうしばらく続きそうです。しかし、グローバルの状況をみると、Google Cloudは、AWSの4割くらいまで届いているので、日本でも Google Cloud はまだまだ伸びる余地はありそうです。
みんなで頑張って、Google Cloud のすばらしさをもっともっと広めていきましょう!
ハルシネーション
もう一つハルシネーションのお話です。ハルシネーションについてググったら以下のような説明でした。
ハルシネーションとは、人工知能(AI)が事実に基づかない情報を生成する現象のことです。まるでAIが幻覚(ハルシネーション)を見ているかのように、信憑性のある嘘を生成することがあります。
例えば、例えば、AIに「2020年のノーベル平和賞受賞者は誰ですか?」と質問した際に、実際には存在しない人物名を答えることがあります。
これは困りますよね。これでは生成AIを業務に組み込むなんて不可能です。
生成AIが広まりだしたころ、ハルシネーションが問題だと色々なところで、騒がれていましたが、最近あまり聞かなくなりました。それどころか、ハルシネーション問題を無視して、生成AIの良い所ばかりがアピールされている感さえもあります。
ということで、最近のハルシネーションはどんな状況だろうと調べてみました。
これはGithubのリポジトリから得た情報ですが、各LLMのハルシネーション発生率を調査したものです。
Top10は、以下の通りです。Google Gemini 2.5 Proが1位かと思いきや、なんと1位は2.0 Flash、2位は Gemini 2.0 Proとのことです。10位の Gemini 2.5 Flash でも1.3%という状況です。
Rank Model Name Hallucination Rate
1 Google Gemini-2.0-Flash-001 0.7%
2 Google Gemini-2.0-Pro-Exp 0.8%
3 OpenAI o3-mini-high 0.8%
4 Vectara Mockingbird-2-Echo 0.9%
5 Google Gemini-2.5-Pro-Exp-0325 1.1%
6 Google Gemini-2.0-Flash-Lite-Preview 1.2%
7 OpenAI GPT-4.5-Preview 1.2%
8 Zhipu AI GLM-4-9B-Chat 1.3%
9 Google Gemini-2.0-Flash-Exp 1.3%
10 Google Gemini-2.5-Flash-Preview 1.3%
そこで、ふと思いました。果たして人間は0.0%なのか。そんなことないですよね。1.3%よりももっともっと大きい気もするので、生成AIは人間をもう超えているのかもしれません。ここから先は指数関数的に生成AIは成長していき、3年後には全く違った世界が待っていることでしょう。工場で働いているのはAIロボットだけで、無人運営されているなんて当たり前で、新しい技術をAIが開発し、AIがカンファレンスなどで発表し、それを聞いているのもAI達。人間はAIのいうことを聞いて働くだけ。。。。自分で書いてて怖くなったのでここでやめておきます。
じゃ、また!
Taka
Alphabet 四半期決算 最終利益46%増の約4.9兆円。過去最高。
Google 生成AI Gemini 2.5 Flash
こんにちは、Takaです。
色んな会社が、生成AIを次々と発表していて、よくわからん。
そんなお悩みわかります。私も日々同じ思いですが、少しでも助けになればと思い、今回は Gemini 2.5 Flashについて簡単に書いてみます。
Google が展開する Geminiは、最新版として Gemini 2.5 Pro と Gemini 2.5 Flash を公開しています。
簡単に言うと、Gemini 2.5 Proは、非常に高性能で、高品質。最大 200万トークン(GA時予定)と膨大な入力データに対応でき、コーディング能力も大幅に向上したモデルです。
Gemini 2.5 Flash は、速度とコスト効率を考慮した、とてもバランスの取れた生成AIです。
今回は、Gemini 2.5 Flash について、少しだけ掘り下げて記載します。
先程も記載した通り、Gemini 2.5 Flash はコストパフォーマンスを意識したモデルですが、性能は素晴らしく、日常的なタスクから複雑なタスクまで、幅広い用途で高速な処理性能を発揮します。利用者の予算に応じて、思考のオン・オフ設定や、思考予算というものを設定することができるため、簡単なものであれば、お安く使うことができます。
ということで、どのようなタスクに向いているかというと、例えば、簡単なデータ抽出、簡単な説明文作成、ドキュメントの要約などであれば、コスパ良く使えそうですね。難しいものでも、思考予算(Thinking Budget)を設定しておけば、高額にならないので、とても使い勝手が良さそうです。
Googleさんのブログにはトークンあたりの単価も公開されていますが、他社の生成AIに比べてとても安いです(これはサービスを売る立場としては、とても複雑な心境ですが笑)。一体どこまで進化するんだGemini!という思いですが、まずは Gemini 2.5 Flashを使い倒してみようと思います。
では、また!
Taka
【セッションレポート】Google Cloud で使える Oracle Database の利用パターン
こんにちは、Zakiです。
2024年に Oralce と Google Cloud のパートナーシップが強化され、Oracle Database はGoogle Cloud 上で柔軟な利用が可能になりました。
ただ実際のところ、どのような提供パターンがあるのかよく分かっていなかったのですが、Google Cloud Next '25 のセッションで解説がありましたので、ご紹介いたします!
まず、利用パターンとしては、大きく3つあります。

それぞれ特徴を簡単にまとめると、
01:Oracle Database @ Google Cloud
※多分、Google Cloud上でOracleを使う通常の選択肢はこれになる。
・Oracle DatabaseをGoogle Cloud内でネイティブに実行
・Oracle Exadata、Oracle Autonomous Database などのサービスをGoogle Cloud上で利用できる。ラック機能も利用できる。
・ライセンスはマーケットプレイスを通じて提供。よってGoogle Cloud 経由で調達可能。(BYOLはComming Soon らしい)
※ライセンスについての説明はこちら

02:OCI and Google Cross-Cloud Interconnect
・既存のOCI環境でOracle Databaseを実行しているお客様が、Google Cloudの強みを活用したい場合に、両クラウド間の接続して利用する
・Google Cloud側での新規ライセンスの調達は必要なし
・クラウド間を低レイテンシでプライベートかつ安全に接続
※アプリケーションの開発者が2つのクラウドに接続していることを意識させないような、一貫したユーザーエクスペリエンスを提供することを目標とされている、とのこと。
03:Flexible Deployment Option on GCE & GKE
・Google Cloud上でOracle Databaseをネイティブに実行。
・パフォーマンス要件に応じて、環境を柔軟にスケール及びサイズ調整が可能。
※要するに、GCE上に普通にインストールして使うタイプのことだと思う。
そして日本によい発表がこちら。
日本リージョン対応!!

青色、Oracle Database @ Google Cloud が東京&大阪リージョンに展開予定です。
黄色、Cross-Cloud Interconnect も東京リージョン対応予定となっています。
データを日本国内から出したくないニーズは多いと思われますが、
これまでは選択肢は、実質「03:Flexible Deployment Option on GCE & GKE」しかなかったのが、
もう間もなく「01:Oracle Database @ Google Cloud」「02:OCI and Google Cross-Cloud Interconnect」も可能になります!
Google Cloud 上でOracleが使えることで、Google Cloud が得意とするAI活用がぐっと身近になりますから、Oracle ユーザーにとっては嬉しいですね!
2025年とのことですが、具体的に何月からか、という情報はなかったはずなので、引き続き注目していきたいと思います!
本セッションは早速Youtubeで公開されています!
気になる方はぜひご参照くださいね!
Supercharge your Oracle databases and applications with Google Cloud
本文中のImageはYoutubeからの引用です